F. Exporter des données
- Choisir le format d’export
- Exporter au format tableur (CSV)
- Exporter au format SIG (GeoJSON)
- Exporter au format WFS
- Signification des champs
- Précautions concernant l’utilisation des données
1. Choisir le format d’export
Une fois une recherche réalisée, il est possible d’exporter ses résultats sous différents formats :
- au format tableur (CSV)
- au format SIG (GeoJSON)
- sous la forme de flux (WFS)
- Les deux derniers formats sont uniquement accessibles aux utilisateurs disposant d’identifiants de connexion.
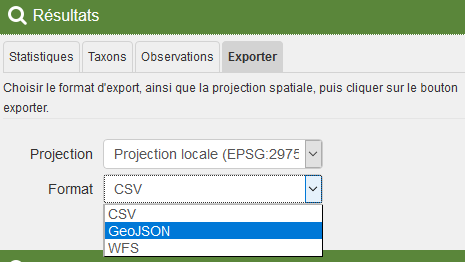
Il est également possible de choisir la projection souhaitée :
- projection locale officielle: RGR92 / UTM zone 40S (EPSG = 2975)
- longitude/latitude, souvent utilisée par les GPS : WGS84 (EPSG = 4326)
Pour exporter et choisir le format et la projection voulus, cliquez sur l’onglet “Exporter” du panneau “Résultats” puis sur le petit bouton situé à gauche de la loupe.
2. Exporter au format tableur (CSV)
2.1 Enregistrer le fichier compressé
Si le format CSV a été sélectionné pour l’export des données, une fenêtre s’ouvre demandant d’ouvrir ou enregistrer le fichier export_observation.zip. Enregistrez le fichier sur votre disque dur, puis dézippez-le avec un logiciel de gestion d’archives (par exemple avec WinRAR).
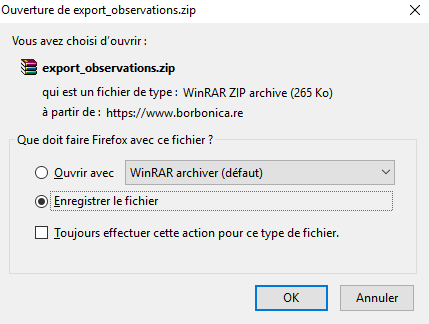
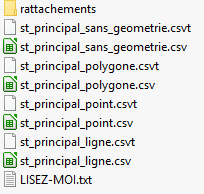
Le dossier dézippé contient les éléments suivants correspondant à la requête :
- st_principal__typegeometrie_.csv : données d’observation, réparties en différents fichiers selon la géométrie à laquelle elles sont associées (point, polygone, ligne, pas de géométrie). Les types de géométrie accessibles sont définis par les droits d’accès aux données. Tous les fichiers ont la même structure ce qui facilite la constitution d’un fichier unique si besoin par copier/coller.
- st_principal.csvt : fichier système nécessaire pour gérer les champs du fichier précédent (ne pas ouvrir)
- LISEZ-MOI.txt : métadonnées relatives à l’export
- st_rattachement : dossier comprenant les rattachements des observations à des entités géographiques de référence ainsi que les attributs additionnels associés aux données le cas échéant (uniquement en mode connecté).
- Les attributs additionnels sont des champs non prévus par le format national du SINP mais qu'il est possible de partager de manière standardisée. Ils sont souvent spécifiques à un protocole ou un type de données (ex : biométrie, nom de stations de pêche, identifiant de balise Argos, etc.) et enrichissent souvent grandement les données. Ils peuvent également résulter d'un traitement appliqué aux données source dans Borbonica (ex : calcul de l'altitude à partir du MNT de 10 m). Ils sont uniquement accessibles aux utilisateurs disposant d’identifiants de connexion.
- Pour plus de lisibilité, il est recommandé d’ouvrir les fichiers contenus dans le dossier d'export à l’aide du logiciel Libre Office Calc (encodage : UTF 8 / séparateur : virgule).
2.2 Ouvrir les fichiers principaux
Les fichiers principaux comprennent les principaux champs décrits dans Borbonica. Leur signification est donnée dans la partie dédiée .
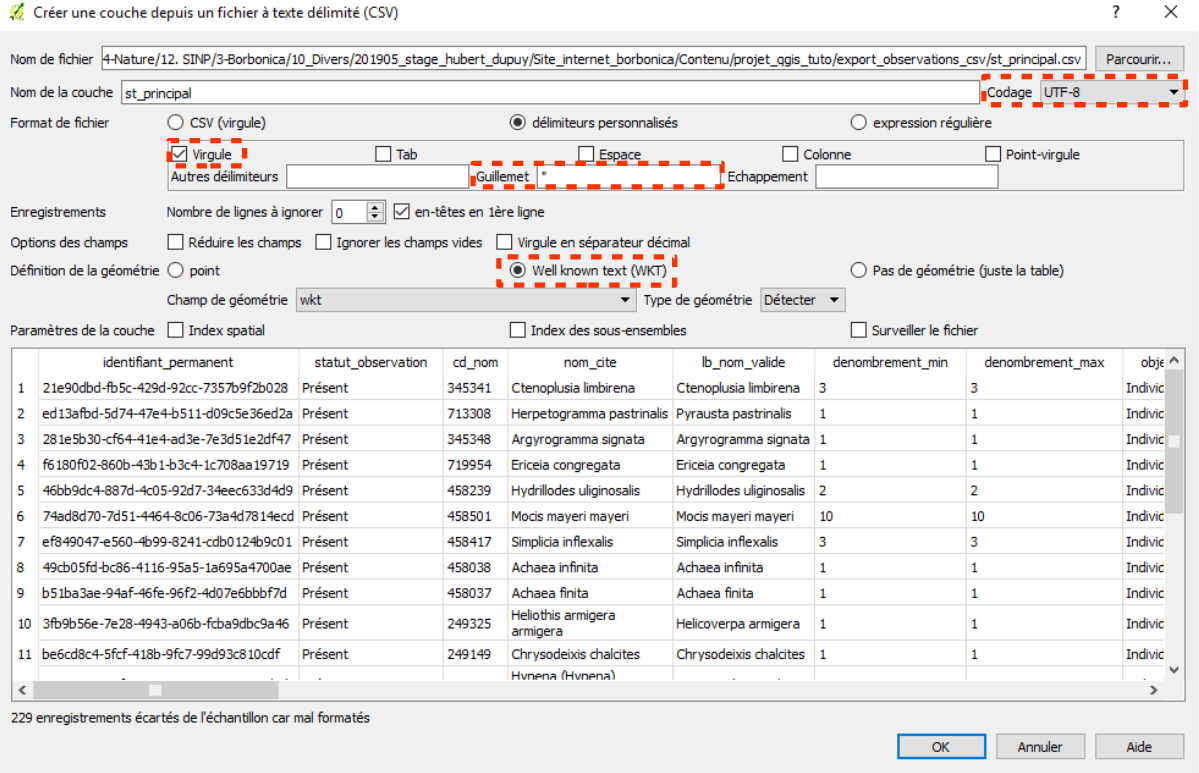
Lorsqu’il est renseigné (voir les modalités d’accès dans la rubrique dédiée ), le champ WKT permet d’accéder à la localisation précise de l’observation en ouvrant le fichier CSV avec un logiciel de SIG. Pour cela, dans QGIS cliquez sur Couche / Ajouter une couche / Ajouter une couche de texte délimité. Renseignez alors comme ci-dessous dans la fenêtre qui s’ouvre le chemin d’accès, les délimiteurs et choisir le format de géométrie Well known text (WKT). Validez ensuite pour ajouter la couche au projet.
2.3 Ouvrir les fichiers associés
Le dossier est composé de plusieurs fichiers :
- st_commune : localisation à la commune
- st_departement : localisation au département
- st_maille_02 : localisation à la maille 2x2km
- st_maille_10 : localisation à la maille 10x10km
- st_espace_naturel : localisation à l’espace naturel
- st_habitat : localisation à l’habitat naturel (non mis en oeuvre dans Borbonica pour le moment)
- st_masse_eau : localisation à la masse d’eau
- st_attribut_additionnel : attributs additionnels associés aux données le cas échéant. Chaque attribut est caractérisé de manière générique par un nom court, une définition, une valeur, une unité, une thématique de regroupement et un type (QTA = quantitatif / QUAL = qualitatif).
Le lien avec le fichier principal se fait via la colonne cle_obs, commune aux différents fichiers.
2.4 Consulter les métadonnées
Le fichier de métadonnées rappelle les critères de recherche utilisés pour la requête et décrit le contenu du dossier d’export.
Il précise également les conditions d’utilisation des données découlant du protocole national SINP et de la charte régionale SINP.
3. Exporter au format SIG (GeoJSON)
3.1 Enregistrer le fichier compressé
Si le format GeoJSON a été sélectionné pour l’export des données, une fenêtre s’ouvre demandant d’ouvrir ou enregistrer le fichier export_observation.zip. Enregistrez le fichier sur votre disque dur, puis dézippez-le avec un logiciel de gestion d’archives (par exemple avec WinRAR).
Le dossier dézippé contient deux fichiers correspondant à la requête :
- export_observations.geojson : données d’observation
- LISEZ-MOI.txt : métadonnées relatives à l’export.
3.2 Consulter les données
Le format GeoJSON est un format de données géolocalisées vectorielles manipulable sous un logiciel de SIG à l’instar d’autres formats de données plus courants (ex : .shp, .tab…). Il présente l’avantage de contenir l’ensemble des informations dans un unique fichier.
Sous QGIS, l’ouverture de la couche GeoJSON s’effectue comme toute couche vecteur via le menu Couche / Ajouter une couche / Ajouter une couche vecteur ou via le bouton raccourci des barres de menu.
- Il est également possible de « glisser - déplacer » la couche en la « jetant » sur la fenêtre carte de QGIS depuis son répertoire de stockage
Lorsque l’export contient des objets de nature différente, une fenêtre s’ouvre demandant quelle(s) couche(s) vectorielle(s) sélectionner et affiche le détail du nombre de données par type de géométrie (point, ligne, polygone). En effet, QGIS et la plupart des logiciels de SIG gèrent les objets de types différents dans des couches différentes. Si tous les types de données vous intéressent, sélectionnez toutes les couches puis cliquez sur « OK ».
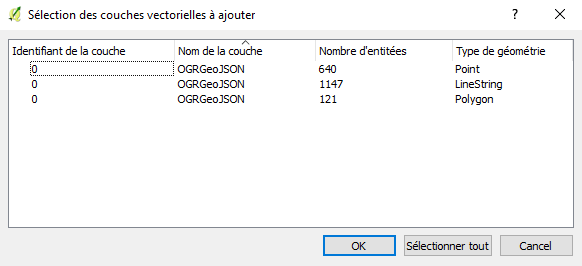
La ou les couche(s) correspondante(s) s’ouvre(nt) alors dans la fenêtre carte.
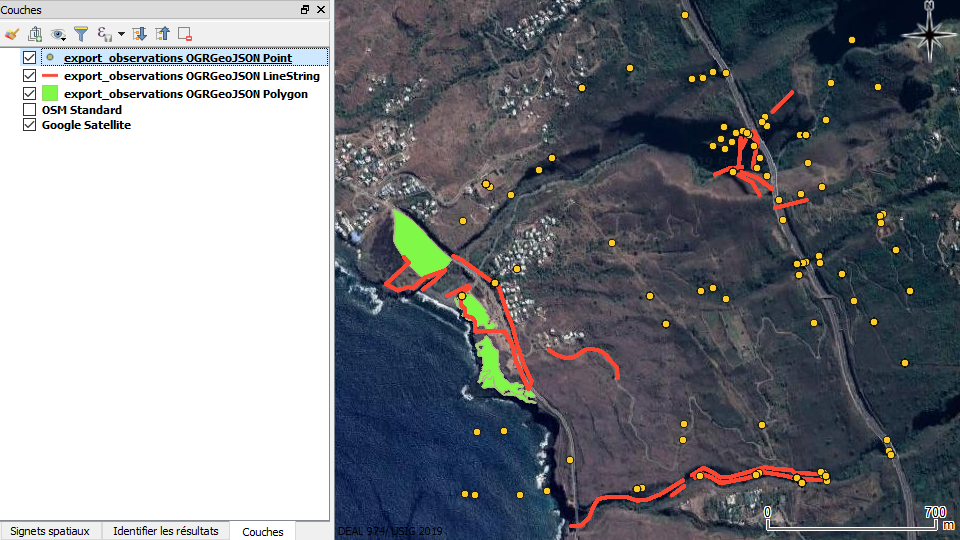
- En cas de problème d’affichage sous SIG (décalage par rapport à un fond de carte par exemple), pensez à vérifier que la projection de la couche correspond bien à ce que vous avez choisi au moment de l'export. Pour cela, allez dans les propriétés de la couche, puis sélectionnez le bon système de coordonnées de référence.
- Les données sont encodées en UTF8. En cas de problème d’affichage de caractères spéciaux dans les attributs (accents mal retranscrits par exemple), allez dans les propriétés de la couche, puis sélectionnez le bon encodage des données source.
3.3 Consulter les métadonnées
Le fichier de métadonnées rappelle les critères de recherche utilisés pour la requête et décrit le contenu du dossier d’export.
Il précise également les conditions d’utilisation des données découlant du protocole national SINP et de la charte régionale SINP.
4. Exporter au format WFS
4.1 Intérêts du format WFS
Le format WFS (Web feature service) permet, au moyen d’une URL formatée, d’interroger des serveurs cartographiques distants afin de manipuler des objets géographiques (lignes, points, polygones…), contrairement au Web Map Service ou WMS qui ne permet que la production de cartes. Son utilisation requiert un accès à Internet.
Le format WFS donne accès à un flux de données récupéré en temps réel sur le serveur hébergeant Borbonica. Si de nouvelles données correspondant à la requête de l’utilisateur ont été intégrées à Borbonica entre le moment de la première requête et le moment où il se connecte, ces données lui seront donc accessibles depuis son logiciel de SIG sans qu’il ait besoin de faire une nouvelle requête sur Borbonica.
4.2 Récupérer l’adresse correspondant à la requête
Si le format WFS a été sélectionné pour l’export des données, un champ apparaît stockant une adresse URL.
Pour visualiser les données, il faut dans un premier temps copier cette adresse, par exemple : https://www.borbonica.re/carte/index.php/occtax/wfs/?date_min=1887-05-01&code_commune=97423&service=WFS&request=GetCapabilities&version=1.0.0 .
L’URL du flux intrègre les critères de recherche utilisés pour la générer.
4.3 Ouvrir le flux dans QGIS
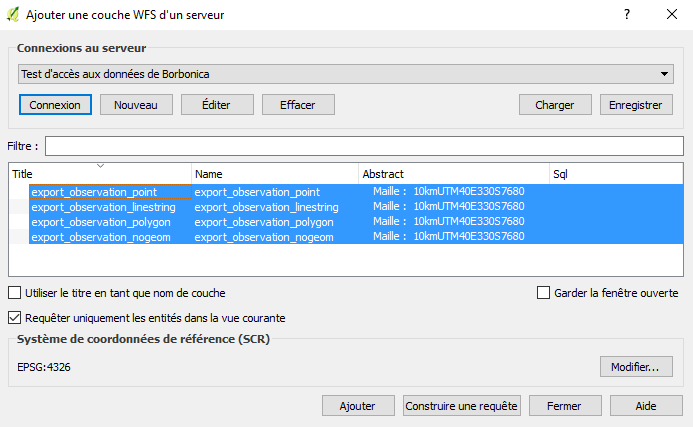
Ouvrez QGIS puis allez dans le menu Couche / Ajouter une couche / Ajouter une couche WFS. La fenêtre suivante s’ouvre alors :
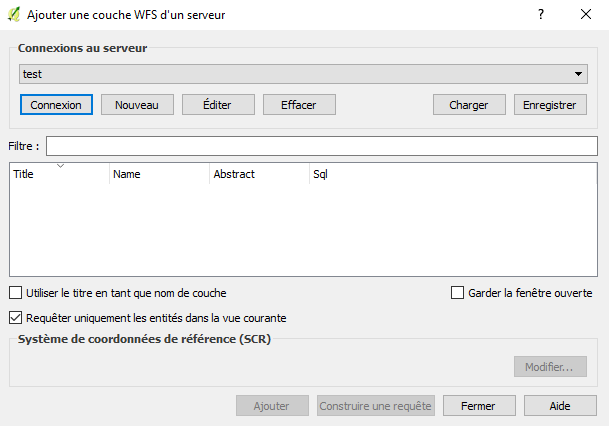
- La fonctionnalité n'est pas offerte pour les versions anciennes de QGIS. Une version au moins égale à la 2.18 est nécessaire pour visualiser les flux WFS. Une version récente de QGIS peut être librement téléchargée sur le portail de QGIS https://qgis.org/fr/site/forusers/download.html.
Cliquez sur nouveau puis renseignez les identifiants de connexion ainsi :
- Nom : nom de votre choix permettant de désigner cette connexion
- URL : adresse copiée dans le navigateur Internet
- Nom d’utilisateur : login qui vous a été fourni par l’administrateur Borbonica
- Mot de passe (optionnel): mot de passe qui vous a été fourni par l’administrateur Borbonica.
Cliquez ensuite sur “OK” puis sur “Connexion”. La liste des couches accessible via le flux est actualisée. Elle comprend 4 couches :
- export_observation_point : couches des observations de type point
- export_observation_linestring : couches des observations de type ligne
- export_observation_polygon : couches des observations de type polygone
- export_observation_nogeom : couches des observations non associées à une géométrie précise (en réalité elles sont associées soit à une maille soit au département sans plus de précision).
Sélectionnez toutes les couches ou uniquement celle souhaitée, puis cliquez sur “Ajouter”. Les couches apparaissent alors dans la fenêtre carte de QGIS et sont manipulables comme toute autre couche vectorielle.
- Si vous enregistrez le projet QGIS après avoir ajouté la couche issue du flux, le mot de passe sera stocké en dur dans le projet QGIS. Il est important de prendre des précautions dans le cas où le projet serait transmis à d'autres utilisateurs, qui disposeraient alors des droits d'accès qui vous sont ouverts sans qu'un mot de passe ne leur soit demandé.
5. Signification des champs
Borbonica met en oeuvre le format standard national occurrences de taxon (version 2.0) . La signification des champs exportés aux différents formats est détaillée ci-desous. Lorsqu’il s’agit d’un champ à vocabulaire contrôlé, la liste des valeurs possibles est accessible en cliquant sur le symbole .
5.1 Table principale
La table principale comporte les observations générales relatives au taxon observé, au lieu et à la date d’observation, ainsi qu’à l’observateur. Les champs indiqués d’une * sont accessibles aux seuls utilisateurs disposant d’identifiants de connexion.
Champ |
Signification |
|---|---|
| cle_obs | Identifiant technique de l’observation dans Borbonica, utile notamment pour faire le lien entre les différents fichiers de l’export csv |
| id_sinp_occtax | Identifiant unique et permanent de l’observation dans le SINP attribué par Borbonica ou la plate-forme nationale du SINP |
| statut_observation * | Indique si le taxon a été observé directement/indirectement (indices de présence), ou bien non observé |
| cd_nom | Code du taxon « cd_nom » de TaxRef référençant au niveau national le taxon. Autant que possible au moment de l’échange, le référentiel utilisé est celui en vigueur diffusé sur le site de l’INPN ( https://inpn.mnhn.fr/programme/referentiel-taxonomique-taxref ) |
| nom_cite | Nom du taxon cité à l’origine par l’observateur. Celui-ci peut être le nom scientifique reprenant idéalement en plus du nom latin, l’auteur et la date. Cependant, si le nom initialement cité est un nom vernaculaire ou un nom scientifique incomplet alors c’est cette information qui doit être indiquée |
| lb_nom_valide | Nom latin du taxon de référence rattaché au nom cité à partir de Taxref |
| nom_vern | Nom français du taxon issu de Taxref |
| group2_inpn | Groupe taxonomique |
| famille | Famille taxonomique |
| loc | Statut biogéographique issu de Taxref |
| menace | Niveau de menace sur la liste rouge UICN des espèces menacées de La Réunion |
| protection | Statut de protection du taxon |
| denombrement_min * | Nombre minimum d’individus du taxon composant l’observation |
| denombrement_max * | Nombre maximum d’individus du taxon composant l’observation |
| objet_denombrement * | Objet sur lequel porte le dénombrement (exemple : individu, couple…) |
| type_denombrement * | Méthode utilisée pour le dénombrement (exemple : calculé, compté…) |
| commentaire * | Champ libre pour informations complémentaires indicatives sur le sujet d’observation |
| date_debut | Date du jour de début d’observation. En cas d’imprécision, cet attribut représente la date la plus ancienne de la période d’imprécision |
| date_fin | Date du jour de fin d’observation. En cas d’imprécision, cet attribut représente la date la plus ancienne de la période d’imprécision. Lorsqu’une observation est faite sur un jour, les dates de début et de fin sont les mêmes (cas le plus courant) |
| dee_date_derniere_modification * | Date de dernière modification de la donnée |
| ds_publique * | Indique explicitement si la donnée est d’origine publique ou privée. La charte régionale du SINP 974 prévoit que les données d’origine publique soient diffusées sans floutage au grand public, sauf pour les données sensibles. |
| id_origine | Identifiant unique de la donnée source de l’observation dans la base de données du producteur où est stockée et initialement gérée la donnée source |
| jdd_code | Code du jeu de données dont provient la donnée source |
| id_sinp_jdd | Identifiant permanent et unique de la fiche métadonnées du jeu de données auquel appartient la donnée. Cet identifiant est attribué par la plate-forme |
| organisme_gestionnaire_donnees | Organisme détenant la donnée source à l’origine de la |
| statut_source | Indique si la donnée source de l’observation provient directement du terrain (via un document informatisé ou une base de données), d’une collection, de la littérature, ou n’est pas connu |
| reference_biblio * | Référence de la source de l’observation lorsque celle-ci est de type « Littérature », au format ISO690 |
| sensi_niveau | Indique si l’observation et à quel degré selon le référentiel de sensibilité du SINP 974 |
| descriptif_sujet * | Voir le tableau ci-dessous |
| validite_niveau | Niveau de validité de la donnée attribué à partir du protocole régional de validation du SINP 974 |
| validite_date_validation | Date d’attribution du niveau de validité |
| precision_geometrie | Précision de la géométrie (en m). Cette valeur peut faire l’objet d’estimations lorsqu’elle n’est pas présente dans la donnée d’origine |
| wkt | Champ comprenant la géométrie de l’observation au format Well Known Text dans le fichier d’export au format csv uniquement. L’information n’est disponible au grand public que pour les données non sensibles d’origine publique ou dont le producteur a accepté une diffusion non floutée. Les ayants-droit accèdent en revanche aux données précises |
| observateur | Nom, prénom, et organisme de la ou des personnes ayant réalisé l’observation. Cette information n’est pas diffusée si le producteur de données a indiqué que les personnes concernées par son jeu de données souhaitaient rester anonymes |
5.2 Sujets d’observation
Les sujets d’observation sont décrits dans le champ descriptif_sujet de la table principale. Le champ comprend un item par groupe d’individus homogènes (ex : des mâles adultes, des juvéniles au sexe indéterminé…). Chaque groupe est compris entre des accolades { }. La signification des champs des différents fichiers est la suivante :
Champ |
Signification |
|---|---|
| occ_sexe | Sexe du sujet de l’observation |
| obs_technique | Indique de quelle manière on a pu constater la présence d’un sujet d’observation |
| obs_contexte | Description libre du contexte de l’observation, aussi succincte et précise que possible |
| occ_naturalite | Naturalité de l’occurrence, conséquence de l’influence anthropique directe qui la caractérise. Elle peut être déterminée immédiatement par simple observation, y compris par une personne n’ayant pas de formation dans le domaine de la biologie considéré |
| obs_description | Description libre de l’observation, aussi succincte et précise que possible |
| occ_stade_de_vie | Stade de développement du sujet de l’observation |
| preuve_existante | Indique si une preuve existe ou non. Par preuve on entend un objet physique ou numérique permettant de démontrer l’existence de l’occurrence et/ou d’en vérifier l’exactitude |
| url_preuve_numerique | Adresse web à laquelle on pourra trouver la preuve numérique ou l’archive contenant toutes les preuves numériques (image(s), sonogramme(s), film(s), séquence(s) génétique(s)…) |
| occ_etat_biologique | Etat biologique de l’organisme au moment de l’observation (vivant, mort, etc.) |
| occ_statut_biologique | Statut biologique de l’individu observé (reproduction, hibernation, en vol, etc.) |
| occ_methode_determination | Description de la méthode utilisée pour déterminer le taxon lors de l’observation |
| occ_statut_biogeographique | Le statut biogéographique couvre une notion de présence (présence/absence), et d’origine (indigénat ou introduction). Il est similaire au statut biogéographique du guide méthodologique TAXREF mais s’applique au niveau local : il s’agit d’une information qui ne peut être renseignée que suite à une déduction à dire d’expert |
| occ_comportement | Comportement de l’individu sur le site d’observation |
| denombrement_min | Nombre minimum d’individus du taxon composant le groupe d’individus |
| denombrement_max | Nombre maximum d’individus du taxon composant le groupe d’individus |
| objet_denombrement | Objet sur lequel porte le dénombrement (exemple : individu, couple…) |
| type_denombrement | Méthode utilisée pour le dénombrement (exemple : calculé, compté…) |
5.3 Tables de rattachement
L’export csv comprend des tables de rattachement des observations à des entités géographiques de référence (voir la partie dédiée ). La signification des champs des différents fichiers est la suivante :
Champ |
Signification |
|---|---|
| cle_obs | Identifiant unique technique de la donnée dans Borbonica |
| code_maille | Code de la maille à laquelle est rattachée l’observation |
| version_ref | Version du référentiel de maille |
| nom_ref | Nom du référentiel de maille |
| type_info_geo | Indique le type d’information géographique (« géoréférencement » lorsque la maille est la seule information géographique disponible dans la donnée source, « rattachement » lorsqu’il s’agit d’une information déduite par croisement entre la géométrie de la donnée source et la couche des mailles) |
6. Précautions concernant l’utilisation des données
Différentes précautions sont à mettre en oeuvre pour ne pas conduire à surinterpréter ou interpréter de manière erronnée les données issues de Borbonica. Dans tous les cas, cela implique une nécessaire prise en compte des attributs des données en ne se limitant pas à la seule donnée de localisation des observations.
6.1 Non exhaustivité des données
Les données diffusées dans Borbonica reflètent l’état d’avancement à un moment donné de la mise en partage des données dans le cadre du SINP. Elles ne doivent en aucun cas être considérées comme exhaustives.
L’absence dans Borbonica d’observation d’une espèce sur un secteur donné peut en effet indiquer :
- soit que des observations ont été réalisées mais n’ont pas été versées à Borbonica ;
- soit que l’espèce n’a pas encore été prospectée sur le secteur ;
- soit que l’espèce a été cherchée mais n’a pas été trouvée. Dans ce cas, il est possible d’indiquer que l’espèce n’a pas été observée via le champ statut_observation (voir plus haut ), mais ces observations sont rarement consignées par les producteurs pour le moment.
A l’inverse, l’existence d’une observation pour une espèce donnée sur un secteur donné ne signifie pas forcément que l’espèce y est toujours. En effet, l’observation peut être ancienne (regarder les champs date-debut et date-fin), ou bien il peut s’agit d’une espèce mobile (pour la faune).
6.2 Niveau de validité des données
Les données intégrées dans Borbonica font l’objet d’une validation scientifique dans le cadre du protocole de validation du SINP 974 . Cette procédure conduit à attribuer un indice de fiabilité aux données sur la base des connaissances disponibles. Chaque observation se voit donc attribuer un niveau de validité au sein d’une des catégories suivantes :
- Certain / très probable
- Probable
- Douteux
- Invalide
- Non réalisable
- Non évalué
En mode non connecté, seules les observations les plus fiables sont diffusées, correspondant aux niveaux “Certain - très probable” ou “Probable”. En revanche, les utilisateurs disposant d’identifiants de connexion accèdent à l’ensemble des données. Le niveau de validité est stocké dans le champ validite-niveau (voir plus haut ). Le cas échéant, il est nécessaire de filtrer ces données pour n’accéder qu’aux niveaux qui vous intéressent.
6.3 Précision spatiale et taxonomique
Les données intégrées dans Borbonica sont issues de sources variées. Selon les cas, les localisations d’observations peuvent être très précises (de l’ordre du mètre, par exemple pour les points issus de GPS) ou à l’inverse imprécises (de l’ordre de plusieurs centaines de mètres, par exemple pour les observations rattachées à des lieux-dits). Il est important de vérifier cette information dans le champ precision_geometrie.
Selon le même principe, même si la majorité des observations concernent des espèces, le rang du taxon qui fait l’objet d’observation est variable. Il peut ainsi s’étendre d’une variété (ex : Hubertia ambavilla var. taxifolia (Poir.) C.Jeffrey, 1992) à un ordre (ex : Chiroptera Blumenbach, 1779 pour une chauve-souris indéterminée). Par ailleurs, dans certains cas très précis identifiés par le protocole de validation, il peut arriver qu’une donnée signalée par l’observateur au niveau d’une espèce soit validée au niveau du genre.
